Merci pour vos tips !
Je complète avec ce que j’ai appris en faisant l’exercice moi-même aujourd’hui.
On récupère la liste des magasins depuis cette page : https://www.carrefour.fr/magasin
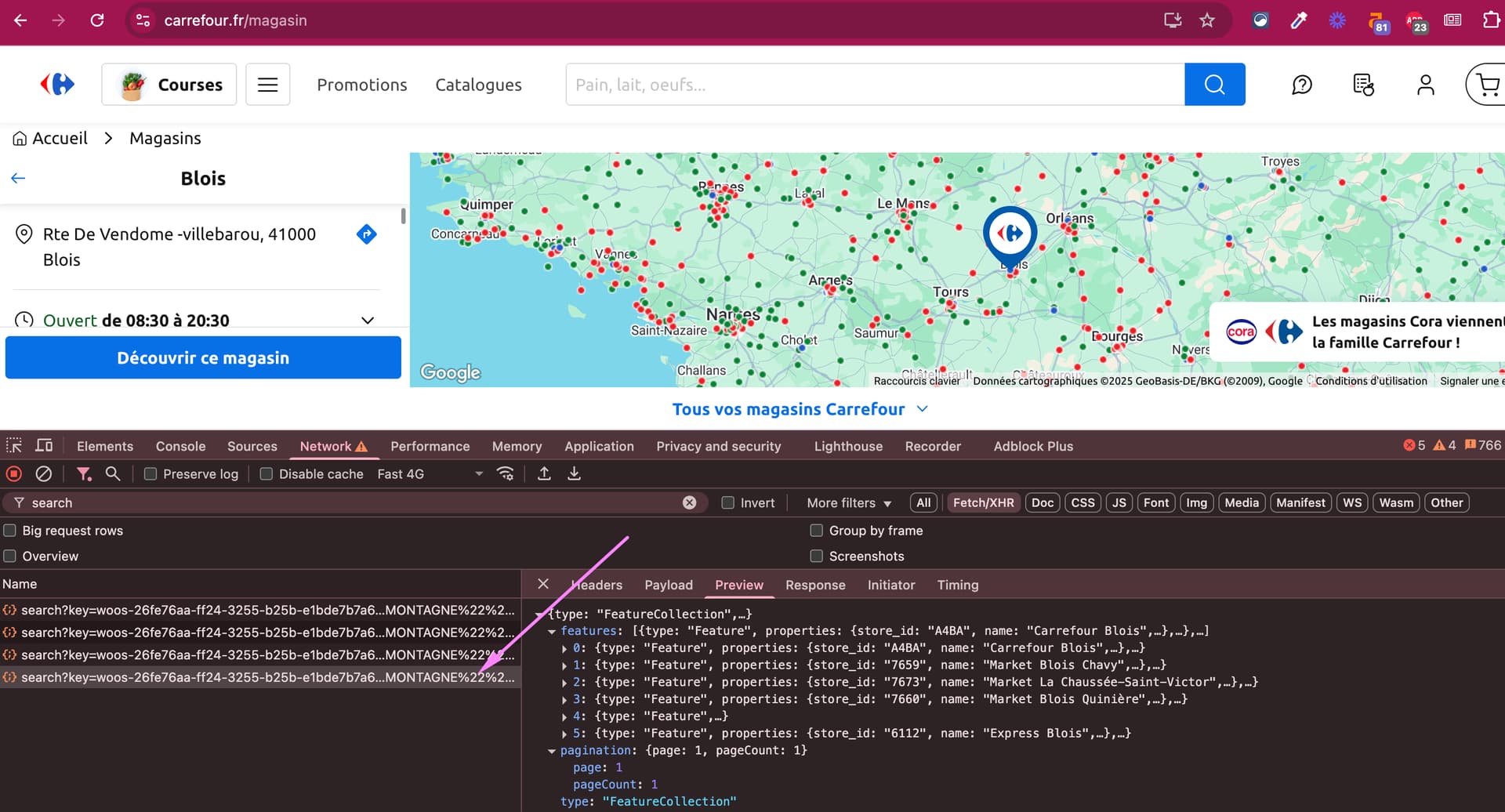
Quand on clique sur un magasin, on obtient un truc comme ça:
Dans la query correspondante, on peut jouer avec deux paramètres :
- La max_distance. Perso je l’ai mise à 5000000
- Le « stores_per_page ». On peut l’augmenter jusqu’à 300.
Et pour extraire automatiquement avec du Python (code généré par Mistral):
import requests
import csv
# Define the API endpoint and parameters
url = "https://api.woosmap.com/stores/search"
api_key = "woos-26fe76aa-ff24-3255-b25b-e1bde7b7a683"
latitude = 47.221201
longitude = 2.0652771
max_distance = 5000000 # Use the original distance
stores_per_page = 300 # Use the original limit
# Define the query parameters
query = (
"(user.banner:\"CARREFOUR\" OR "
"(user.banner:\"CARREFOUR MARKET\" OR user.banner:\"MARKET\") OR "
"user.banner:\"CARREFOUR CONTACT\" OR "
"user.banner:\"CARREFOUR CITY\" OR "
"user.banner:\"CARREFOUR EXPRESS\" OR "
"user.banner:\"CARREFOUR MONTAGNE\" OR "
"user.banner:\"BON APP\")"
)
# Function to fetch data from the API
def fetch_data(page):
params = {
"key": api_key,
"lat": latitude,
"lng": longitude,
"max_distance": max_distance,
"stores_by_page": stores_per_page,
"limit": stores_per_page,
"page": page,
"query": query
}
headers = {
"accept": "*/*",
"referer": "https://www.carrefour.fr/"
}
response = requests.get(url, headers=headers, params=params)
if response.status_code == 200:
return response.json()
else:
print(f"Failed to fetch data: {response.status_code}")
print(f"Response: {response.text}")
return None
# Function to extract relevant data and save to CSV
def save_to_csv(all_stores, filename="carrefour_stores.csv"):
if not all_stores:
return
# Write to CSV
keys = all_stores[0].keys()
with open(filename, "w", newline="", encoding="utf-8") as output_file:
dict_writer = csv.DictWriter(output_file, fieldnames=keys)
dict_writer.writeheader()
dict_writer.writerows(all_stores)
print(f"Data saved to {filename}")
# Fetch the first page to determine the total number of pages
first_page_data = fetch_data(1)
if not first_page_data:
print("Failed to fetch the first page data.")
else:
total_pages = first_page_data.get("pagination", {}).get("pageCount", 1)
print(f"Total pages to fetch: {total_pages}")
# Fetch data for all pages and consolidate into one list
all_stores = []
for page in range(1, total_pages + 1):
data = fetch_data(page)
if data:
for feature in data.get("features", []):
properties = feature.get("properties", {})
store_data = {
"store_id": properties.get("store_id"),
"name": properties.get("name"),
"phone": properties.get("contact", {}).get("phone"),
"website": properties.get("contact", {}).get("website"),
"address": properties.get("address", {}).get("lines", [""])[0],
"city": properties.get("address", {}).get("city"),
"zipcode": properties.get("address", {}).get("zipcode"),
"banner": properties.get("user_properties", {}).get("banner"),
"latitude": feature.get("geometry", {}).get("coordinates", [None, None])[1],
"longitude": feature.get("geometry", {}).get("coordinates", [None, None])[0]
}
all_stores.append(store_data)
# Save all stores to a single CSV file
save_to_csv(all_stores)
A la fin, il suffit de vérifier qu’on a tout en comparant avec l’annuaire « classique »:
https://www.carrefour.fr/magasin/liste