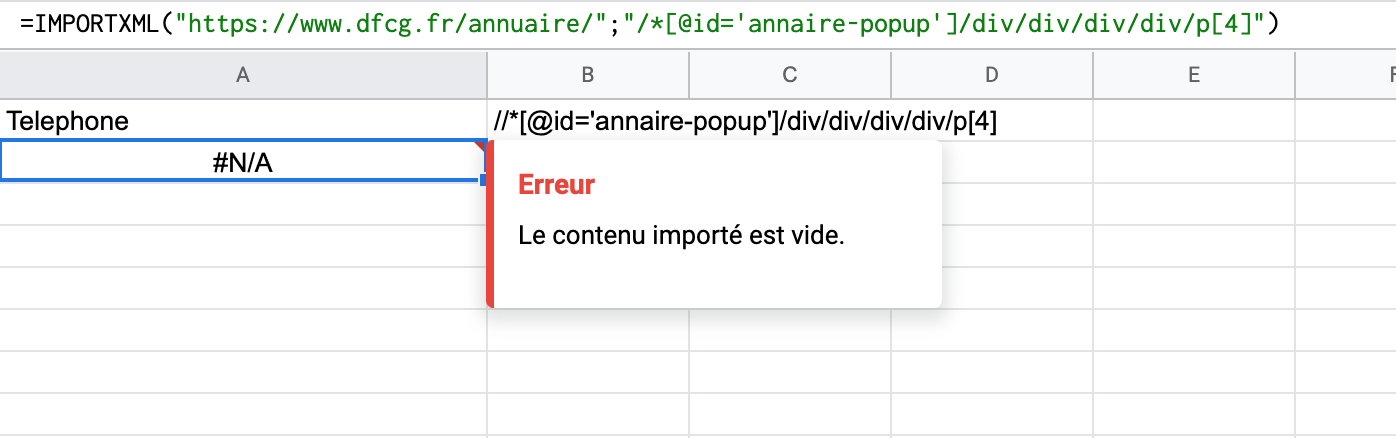
Merci Boris, mais je n’ai pas réussi. Peut-être que je fais mal qlq chose mais mes tests me renvoient toujours une valeur NULL, que ce soit sur Web Scrapper qu’avec IMPORTXML sur Ghseet :
Joke…:
Peut être que si on arrêtait d’écrire « scraper » ou « scraping » , ou même « Web Scraper » avec deux « p » partout, le scraping serait moins vexé et fonctionnerait ?
Vraie réponse:
Il est préférable de ne pas utiliser ni considérer Web Scraper comme un outil « no code », en réalité pour le maîtriser il faut trouver précisément:
où se situe la donnée que l’on souhaite extraire (est-ce le texte d’une balise, ou est-ce la valeur d’un attribut?)
le sélecteur (css dans le cas de Web Scraper) permettant d’identifier le chemin menant à cette data à extrare
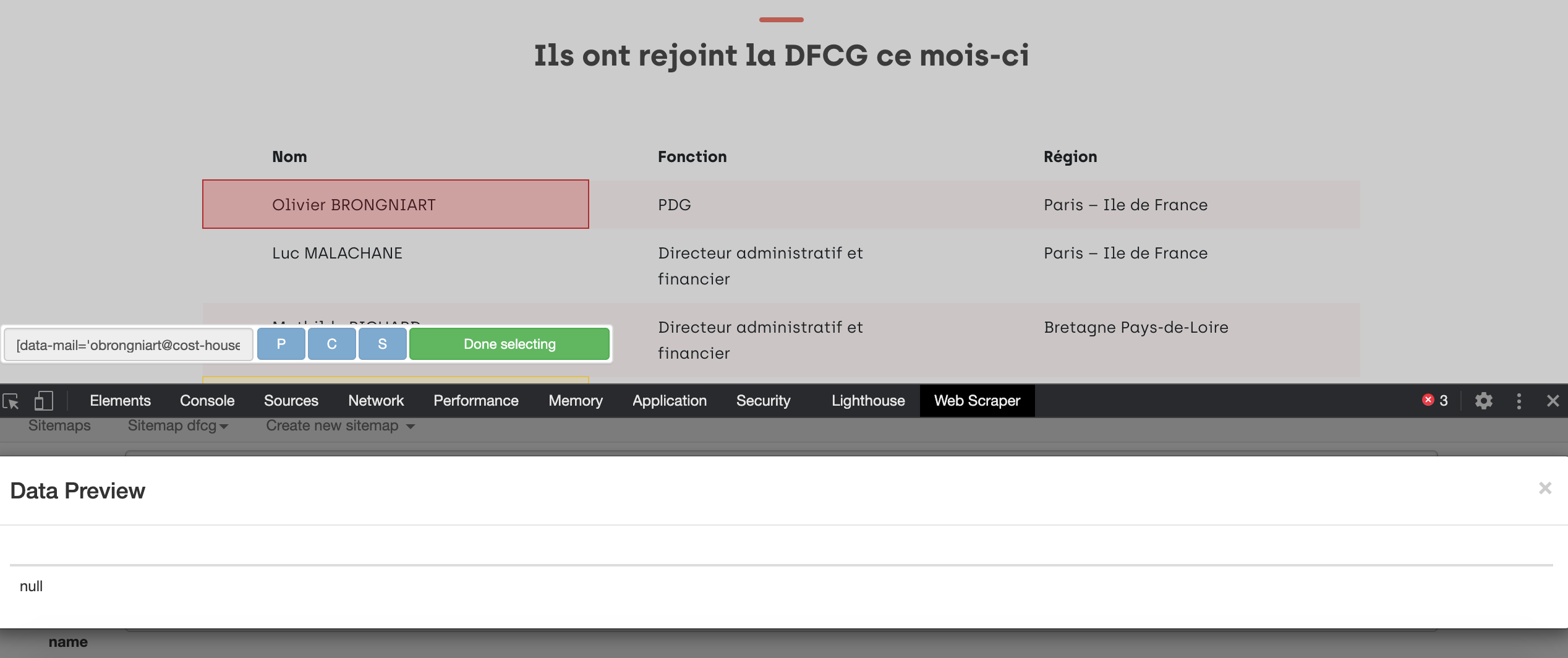
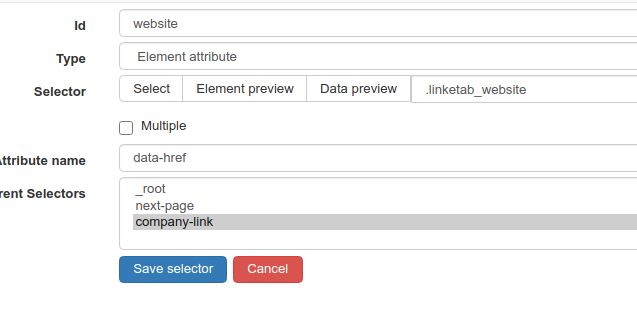
Boris a suggérer de passer par une action de type « Element attribute », ce qui revient à extraire la valeur d’un attribut, une fois qu’on s’est bien positionné sur le bon élément HTML via son sélecteur.
En pratique, il faudra donc remplir deux champs textes, le fameux « selector », et « attribute name », comme dans l’exemple ci dessous:
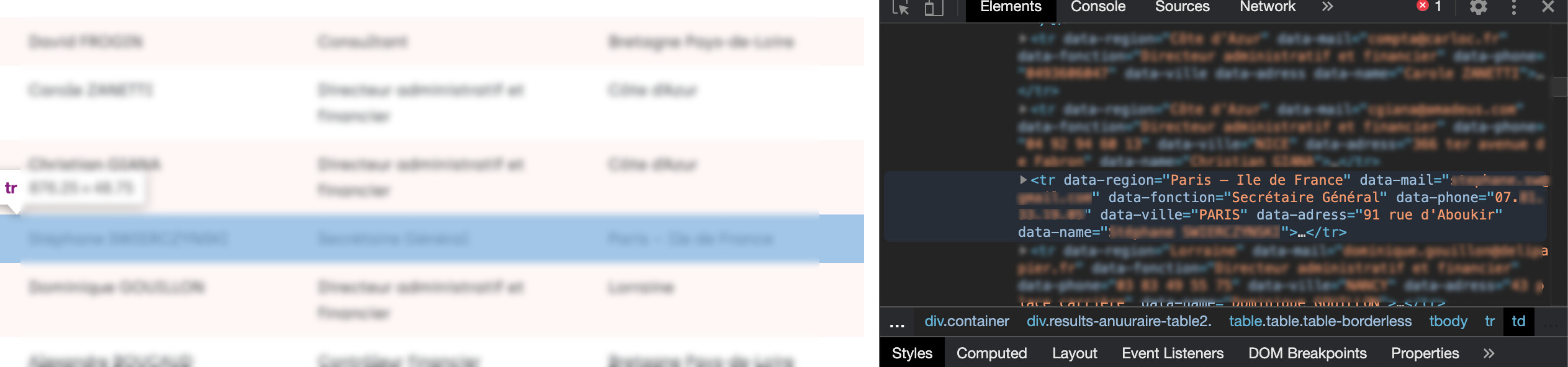
Si la modale est générée dynamiquement (je n’ai pas vérifié), tu la verras dans la console, mais elle n’est pas dans le code source « originel ».
Et pour scraper des pages dynamiques, Selenium reste la meilleure option :