Hello tout le monde!
Je voudrais chopper un fichier stock du flux dirigeants complet sur l INPI mais impossible de mettre la main dessus…
Est ce qu une ame charitable pourrait m aider svp ?
Hello tout le monde!
Je voudrais chopper un fichier stock du flux dirigeants complet sur l INPI mais impossible de mettre la main dessus…
Est ce qu une ame charitable pourrait m aider svp ?
le fichier sur leur FTP date d’octobre 2023 et fait 9Go, il va donc manquer toutes les entreprises créées depuis et celles qui ont changé de dirigeant. Si tu veux quelque chose de plus récent va falloir se retrousser les manches et récupérer les données via API, ou alors trouver quelqu’un qui l’a déjà fait
Merci beaucoup cest ce qu il me semblait… si jamais quelqu un a possibilité d avoir un fichier stock … assez recent je suis preneur
Avec les limitations du nombre d appel ce n est pas demain la veille que j aurai ceci ahah
Je reste en veille n hesitez pas … j ai besoin de cette donnee pour mon memoire .
Salut DataJedi, tu peux créer plusieurs comptes. tu t’en fait une vingtaine en moins d’1 mois tu les as tous récupéré, mais en vrai tu ne le feras pas, car c’est pas simple à faire.
Dis exactement ce que tu veux faire sur les dirigeants, je peux peut être te le faire.
On à toute la data, mais ca c’est un avantage concurrentiel qu’on ne passera pas ![]() comme personne ici. Mais si tu as besoin de stats, etc … avec plaisir
comme personne ici. Mais si tu as besoin de stats, etc … avec plaisir
@Sonic merci pour l info !
Je dois faire des stats assez poussees de repartition de « types de dirigeants » avec repartitions par sexe, fonction ages etc . Je ne sais pas si je m exprime correctement.
Y aurait il selon toi un moyen « raisonnablement » onereux de se procurer ce stock ?
Merci pour ta lumiere en tout cas ![]()
dans ce cas un fichier de fin 2023 devrait te suffire, il y a eu des changements depuis mais pas au point de modifier grandement les statistiques, si tu t’inscrit sur leur portail tu as accès au FTP et au fichier, après faut arriver à exploiter un fichier de 9Go, je pense que c’est du json, tu peux le lire en python/pandas par morceaux (chunks) sinon ton PC va pas apprécier.
Autre solution, choisir un échantillon suffisamment grand de sociétés pour qu’il soit jugé représentatif selon les rêgles de l’échantillonnage statistique
yes le fichier de 2023 doit suffire comme le dit @DJousto ( tu es vraiment de bon conseil)
tu le croises avec le fichier des siren pour que tu es que les sociétés actives ( facile à avoir), et tu devras couplé d’autre open data si tu veux par exemple le CA, l’effectifs…
Attention tu n’as pas le sexe du dirigeant, tu dois faire une bibliothèque pour le genderifier aussi à partir du prenom ( en tout cas c’est comme ca que je fais, ca a peut être changé depuis)
pour le type de dirigeant, ce sont ceux inscrits légalement dans l’entreprise ( tu as gérants, présidents … mais y’en a pas des masses)
il y’a environ 7-8 millions de dirigeants en france.
sinon tu écris les requêtes que tu veux et je te le fais gracieusement à partir d’octobre. il te faut justes les stats ? pas la data
En plus de chunk, tu peux aussi selectionner les colonnes que tu ouvres avec pandas + leurs préatribuer un type. d’expériences ça libère beaaaaauuuucccoooouuppp de ram, et même avec un pc moyen tu peux espérer ouvrir un très gros échantillon.
Merci encore mais en parlant de cela ils n ont pas prevu d actualiser avec une livraison de stock a interval regulier ? Les limitations d appels n ont pas l air folles …
Merci encore mais en parlant de cela ils n ont pas prevu d actualiser avec une livraison de stock a interval regulier ?
si … un an !! c’est un intervalle régulier ![]() en fait on sait pas trop, l’INPI est encore un peu dépassé par les évènements depuis qu’ils ont récupéré la gestion du registre des entreprises, du coup leur API et leur FTP c’est un peu aléatoire, tu sais pas trop quand çà va marcher, y’a pas de support, et leur a du être sous-traitée au pakistan tellement elle est incompréhensible (tout comme l’API)
en fait on sait pas trop, l’INPI est encore un peu dépassé par les évènements depuis qu’ils ont récupéré la gestion du registre des entreprises, du coup leur API et leur FTP c’est un peu aléatoire, tu sais pas trop quand çà va marcher, y’a pas de support, et leur a du être sous-traitée au pakistan tellement elle est incompréhensible (tout comme l’API)
Aligné avec @djousto, j’ajoute un point : avant 2016-2017, il n’y avait pas d’open data tel qu’on la connaît aujourd’hui.
Le royaume de la data B2B était dominé par Kompass, Corporama… Ensuite, l’open data est apparue vers 2016, et @AOnnen a été l’un des premiers pionniers à l’exploiter, avec le « GOAT » de Societinfo, renversant ainsi la donne. La data est devenue gratuite, accessible, et la seule chose à faire était de la « valoriser ». Cependant, les indicateurs montrent que nous faisons marche arrière : on nous a déjà retiré les bénéficiaires effectifs il y a un mois ( sur le coup pappers à trop valoriser cette data en la rendant terriblement sexy, y’a des trucs qui ne plaisent pas) , et j’ai l’intime sensation qu’on cherche à restreindre l’accès à l’information. L’avenir nous le dira, mais je suis persuadé que ce n’est pas un hasard si les données concernant les dirigeants deviennent de plus en plus difficiles à obtenir, etc… Pour avoir un coup d’avance il faut regarder les directives européennes et aussi ce qui se passe dans les autres pays
@Sonic cela semble tres technique et tres politique en effet
Si jamais une bonne ame peut me ping si par miracle un nouveau fichier stock apparait …![]()
![]()
En tout cas merci beaucoup pour toutes ces infos !
Je viens de tomber là dessus, je crois que ton post est entrée dans la légende : Antoine Onnen on LinkedIn: Merci Sonic d’avoir capté ma vision ❤️🙏🏻🙏🏻 8 ans déjà Je me souviens…
Hello guys, et surtout @DataJedi sur le FTP y’a un nouveau fichier, datant de septembre 2024, voilà y’a plus qu’à récupérer les 12Go et les dézipper !! çà te génère 2500 fichiers json !!
@DJousto incroyableeeee.
Il suffisait donc que je pose la question pour que le miracle arrive ? Ahahah
Messieurs je suis en voyage en asie. Connexion totalement pétée (Bali). Ca serait abusé de demander a une ame charitable un petit wetransfer la dessus ?
Si je peux rendre le moindre service en contrepartie … ne pas hesiter (meme un reglement pour le geste …)?
En tout cas merci a la reactivité de la commu ![]()
wetransfert c’est payant pour cette taille de fichier, et je n’ai pas assez de place sur mon google drive, mais bon je voie pas trop en quoi çà t’avance si t’as une connexion pourrie, çà reste un gros fichier à récupérer que çà soit du FTP ou de l’upload web
@DJousto j esperer recup le fichier au detour d un transit civilisé sans avoir a faire toutes les manips pour ceux qui l avaient deja dl. Mais oui je n avais pas pensé a cette contrainte de taille / payant . Merci en tout cas ![]()
J’avais déjà eu la même problématique que toi.
Une fois j’étais passé par Shadow, un PC Gaming a distance (la vitesse était folle) mais pour 200Go, donc là toi tu vas être bloqué niveau capacité de stockage (500Go max je crois)
Donc peut-être monter avec Rclone un stockage distant et « download » directement vers ce stockage monté : FTP, Google Drive, Mega, etc. (enlève la verif de limite de capacité dans Rclone sinon ça ne fonctionne pas)
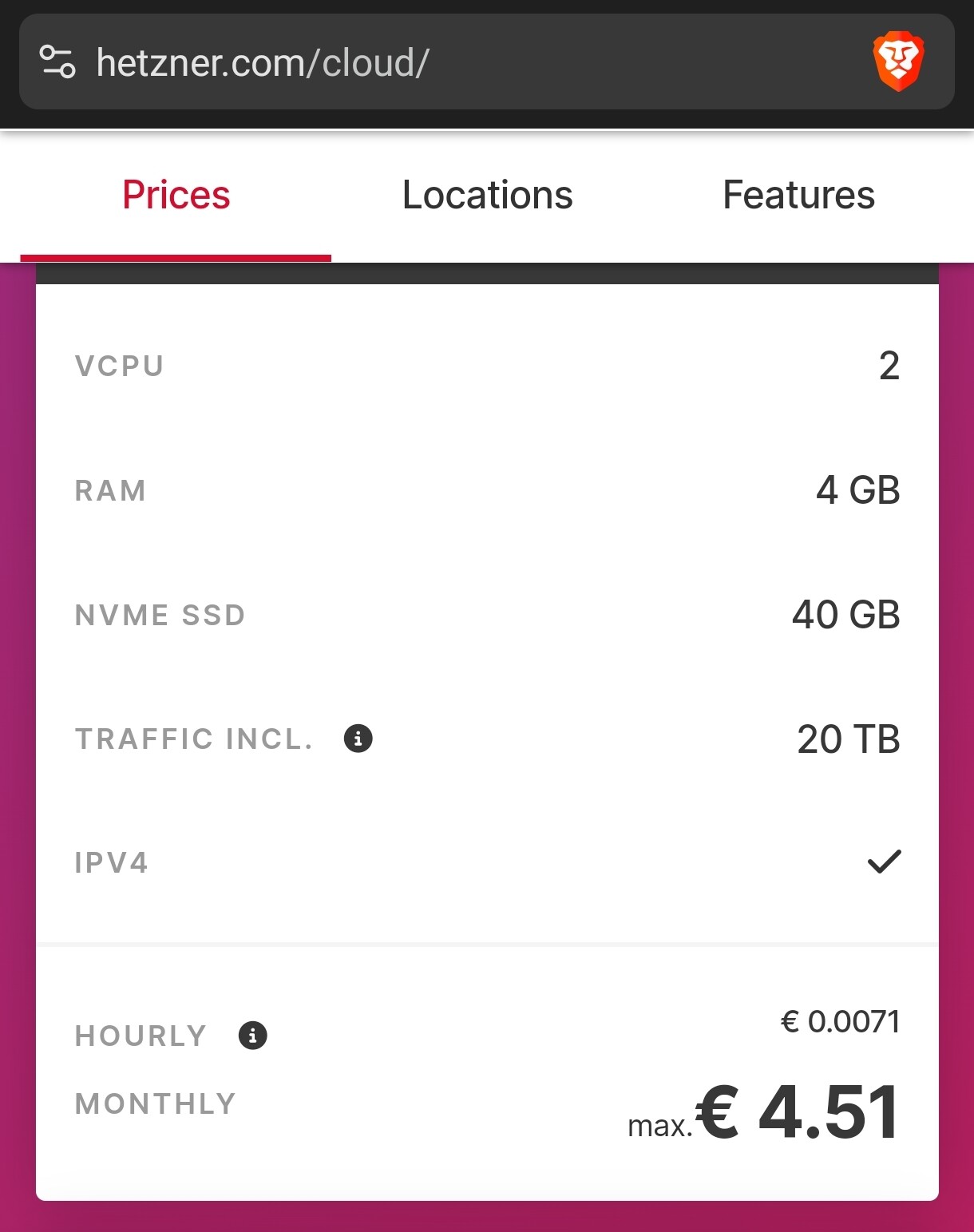
Je l’ai refait y a pas longtemps, mais cette fois je suis passé par un VPS Hetzner (car 20TO de bande passante / mois incluse), et avec Rclone dessus j’ai balancé quasi 4TO d’un Mega vers Google Drive (5j environ )
Pour Google Drive, j’ai souscris à un Google Workspace Turquie sur le plan max (5€ environ / mois / utilisateur. Chaque utilisateur ajoute 5TO au drive d’équipe avec un maximum il me semble)
Il y a aussi une limite journalière d’upload vers Google Drive, de 1 ou 2TO je crois
Peut-être qu’un FTP sur o2switch pourrait aussi le faire, mais voir la limite inode, etc.
Ma problématique a toujours été de stocker et consulter quelques fichiers, pas d’interagir directement avec l’ensemble de ces fichiers. Donc je te laisse creuser ![]()
La vitesse va varier en fonction de ce qui est utilisé pour forward (entrant/sortant) et la cible où tu upload. Mais aussi de la source du téléchargement.
Je te dis ça car je me suis rendu compte que j’avais pas besoin d’un foudre de guerre sur le « forward »
Pour Hetzner il te faudra peut-être plus que le minimum car y aura peut-être pas assez de mémoire pour forward correctement de très gros fichier.