Je dois faire une erreur quelque part mais je ne trouve pas ou :s
Du coup j’ai acheté Webharvy, mais pareil j’ai du mal à scrapper il n’obtient que les noms des restaurs sur la première page.
En gros, tu as juste à importer le JSON que tu as montré, via la fonctionnalité « Import Sitemap »:
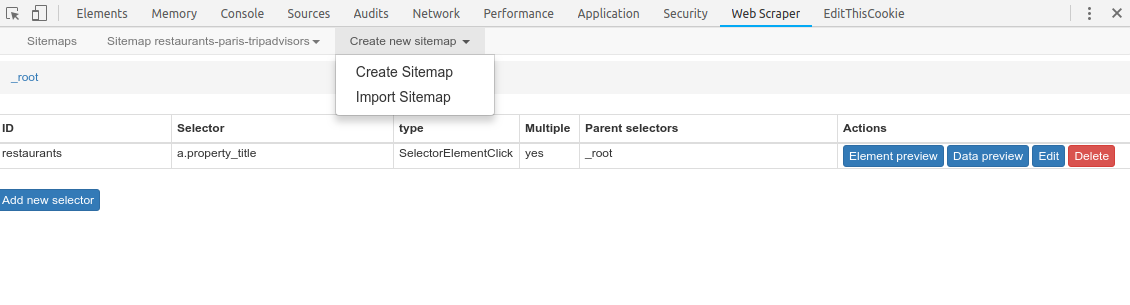
Tu copies colles ce JSON:
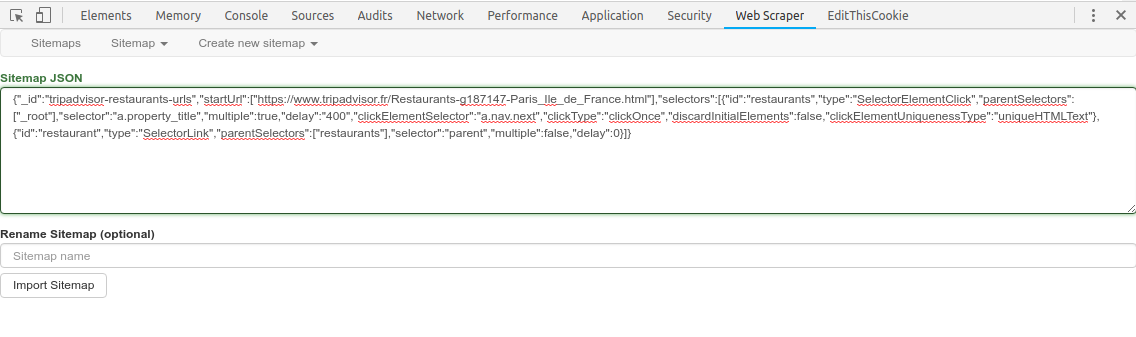
Enfin tu lances le scrap, et ça fonctionne ![]()
1 « J'aime »
Merci pour ton aide, au top! ![]() Je vais réessayer
Je vais réessayer
1 « J'aime »
Je viens de voir ton message.
Peux tu tester avec cette URL de départ STP :
https://www.tripadvisor.fr/Restaurants-g187153-Montpellier_Herault_Occitanie.html
Je n’arrive toujours pas à faire remonter les infos. Pas de différence flagrante dans le contenu des 2 pages pour une éventuelle erreur de selecteurs. Le process se termine bien.
Cela pourrait il venir de Chrome (Version 76.0.3809.100 (Build officiel) (64 bits)) ?
Faut il désactiver toutes les extensions de ce dernier ?
Comprends pas ![]()
Hey sorry, j’étais absent pendant 16 jours, le temps que je relise tous les posts et me remette dedans… je ne pense pas pouvoir te répondre de suite ![]()
Pas de souci. J’espère que les vacances ont été bonnes ![]()
merci pour ce super tuto, lorsque je le lance, le scraping m’indique que s’est terminé instantanément et je n’ai rien. Le code a besoin d’une MAJ peut-être ? Peux-tu m’aider ? Je souhaiterai récupérer les avis aussi ![]()
Hello les amis
![]()
On vient de sortir un tout nouveau crawler no-code juste là:
Et son tuto joliment imagé juste ici:
NB: avec le plan gratuit vous avez 15 minutes par jour çad approx. 300 établissements gratuitement chaque jour — et le @mail est inclus bien entendu
![]()
Très curieux d’avoir vos retours!
1 « J'aime »
Ca marche parfaitement ! Merci !
1 « J'aime »